Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language
In the study titled “Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language,” the authors delve into the critical role of human feedback in the alignment process of large language models (LLMs). They emphasize that learning from human feedback is crucial in improving the performance of these models. Traditionally, feedback signals are collected in the form of ranking preferences, but the authors propose a new approach that allows for richer feedback in the form of textual descriptions.
The current training process for LLMs consists of three core steps. First, the model is pre-trained on a large corpus of data to learn general language patterns and knowledge. Second, supervised fine-tuning is performed to align the model with specific tasks or domains. Finally, there is a step to further align the model’s responses with human preferences. However, this last step presents its own set of challenges.
The authors highlight that training a reward model using reinforcement learning from human feedback (RLHF) is notoriously unstable and requires additional resources to host the policy and base models. Furthermore, the current set of human preferences is limited to a single value, lacking in detail and information.
To address these limitations, the authors propose a novel method that allows for more informative and detailed human feedback. Instead of providing rankings, users can now specify the pros and cons of different generations from the model through textual descriptions. This approach, referred to as “Critique and Revise,” involves generating a critique of the initial response, highlighting both positive and negative aspects, and then revising the response based on the critique.

Example of prompt, response, critique and revised response
To validate their proposed approach, the authors conducted experiments using the Falcon-40B model. They collected critique and revision data with a relatively small amount of labeled data, consisting of 1000 samples. The model was taught human preferences by incorporating the critique into the initial response and revising it accordingly.
The impact of the proposed approach is significant. The authors demonstrate that the Critique and Revise method is able to improve the responses of the ChatGPT level model, leading to a better win-rate of 56.6%. Moreover, after five iterations of revision, the win-rate further improves to an impressive 65.9%.
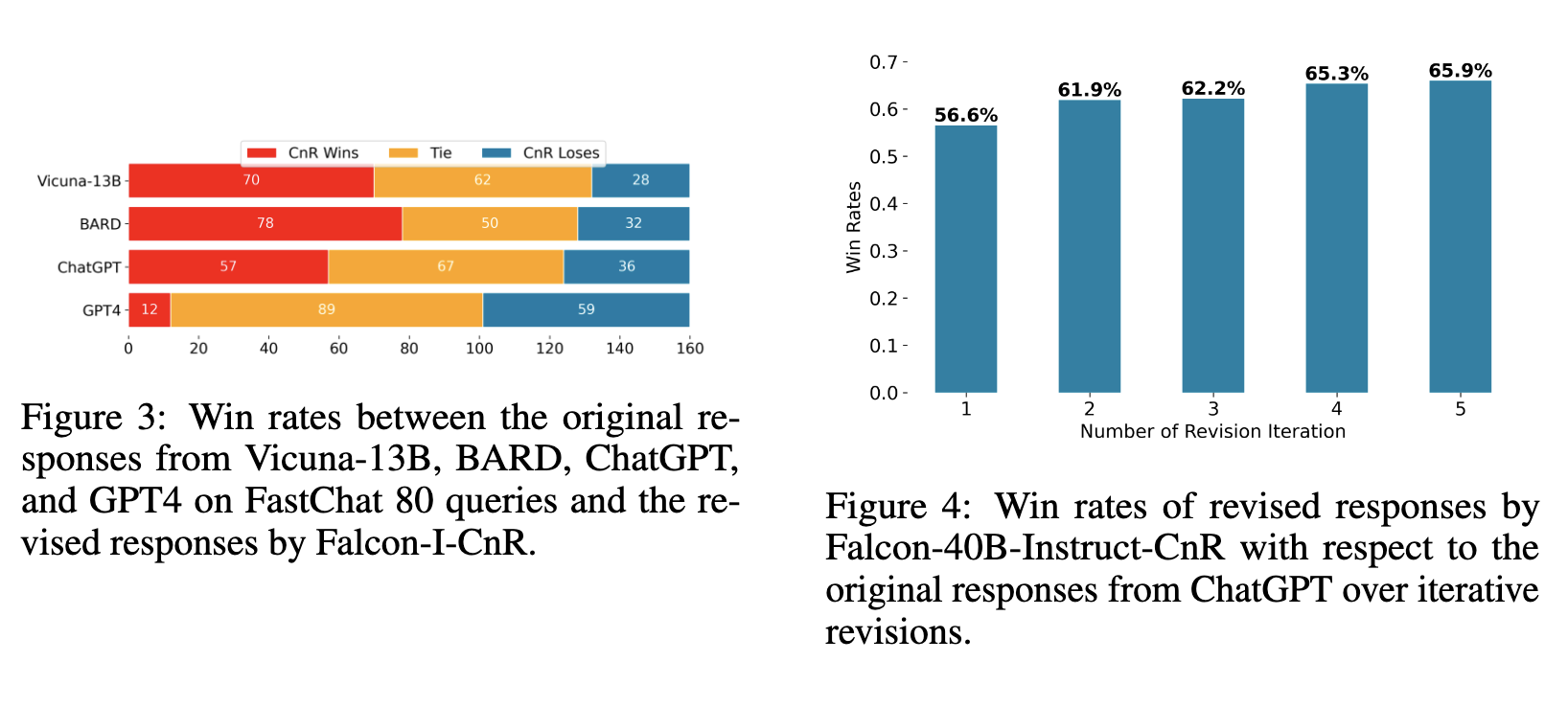
WinRate improvements for ChatGPT, Vicuna models after incorporating the CnR framework
The training workflow for the proposed method is similar to supervised fine-tuning. Each annotated example includes a prompt, initial response, critique, and revised response. The Falcon-40B model is trained using this data, resulting in improved performance and better win-rates for large language models.
In conclusion, this study highlights the importance of incorporating human feedback in the alignment process of large language models. The Critique and Revise method offers a more detailed and informative approach to gathering human preferences, ultimately leading to improved model responses and overall performance. With its data-efficient alignment, this research opens up new possibilities for enhancing the capabilities of language models and advancing the field of natural language processing.
To learn more about the details of this research and its impact, please refer to the original paper.
References
- Jin, Di et al. “Data-Efficient Alignment of Large Language Models with Human Feedback Through Natural Language.” ArXiv abs/2311.14543 (2023): n. pag.