Sample efficient Reinforcement Learning with Human Feedback via Active Exploration
In the field of reinforcement learning, preference-based feedback has become crucial for applications where direct access to the reward function is not feasible. However, a major challenge in utilizing reinforcement learning from human feedback (RLHF) for real-world problems is the high cost of acquiring preference datasets.
Another core problem is aligning large language models (LLMs) with human preferences. The current pipeline involves pre-training the LLMs and then fine-tuning them through supervised learning. Subsequently, RLHF training is performed using preference data over multiple completions generated by the system. This process entails creating a reward model and assigning scores to the LLM’s completions.
As the number of variations required for these LLMs increases, the cost of data annotations becomes the primary bottleneck for training these models.

Sample Efficient Reinforcement Learning from Human Feedback via Active Exploration
To address these challenges, the authors propose a technique that identifies contexts with the largest uncertainty, allowing for the identification of good policies. They frame the problem as an active contextual dueling bandit problem. The core proposal of this paper is the Contextual Borda function, which enables active exploration in reinforcement learning. This approach generates a sampling and policy selection rule to output a policy with provably low sub-optimality. The sampling rule selects contexts with maximum uncertainty over the “Borda value function”.
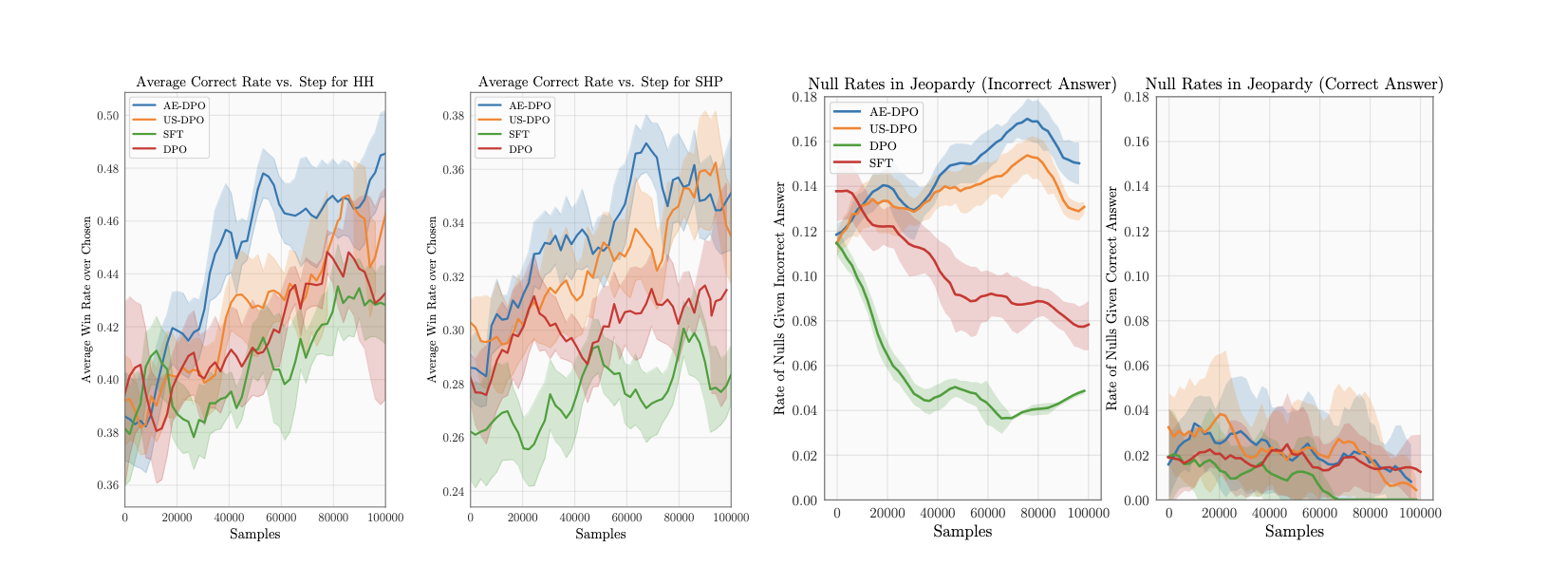
Sample Efficient Reinforcement Learning from Human Feedback via Active Exploration
In their experiments, the authors compare their proposal, AE-Borda, with two other methods: Uniform Borda (which uses uniform sampling for both contexts and actions) and UCB-Borda (which uses uniform sampling of contexts along with UCB actions as in AE-Borda). The results show that the proposed technique achieves similar performance with fewer input samples.
This research has significant implications for sample-efficient reinforcement learning and addresses the challenges of acquiring preference datasets and aligning large language models with human preferences. By identifying contexts of uncertainty, this technique allows for active exploration and the generation of policies with low sub-optimality.
To learn more about the details of this research and its impact, please refer to the original paper.
References
-
Lan, Yixing, et al. ‘Sample Efficient Deep Reinforcement Learning with Online State Abstraction and Causal Transformer Model Prediction’. IEEE Transactions on Neural Networks and Learning Systems, vol. PP, Aug. 2023, https://doi.org10.1109/TNNLS.2023.3296642.
-
Mehta, Viraj, et al. ‘Sample Efficient Reinforcement Learning from Human Feedback via Active Exploration’. arXiv [Cs.LG], 30 Nov. 2023, http://arxiv.org/abs/2312.00267. arXiv.