Direct Preference-based Policy Optimization without Reward Modeling
Preference-based reinforcement learning (RL) has emerged as a promising approach for training RL agents. This innovative approach allows agents to learn directly from preferences, making it particularly useful in situations where formulating a reward function is challenging. However, the process of obtaining an accurate reward model solely from preference information, especially when the preferences come from human teachers, can be a complex and difficult task.
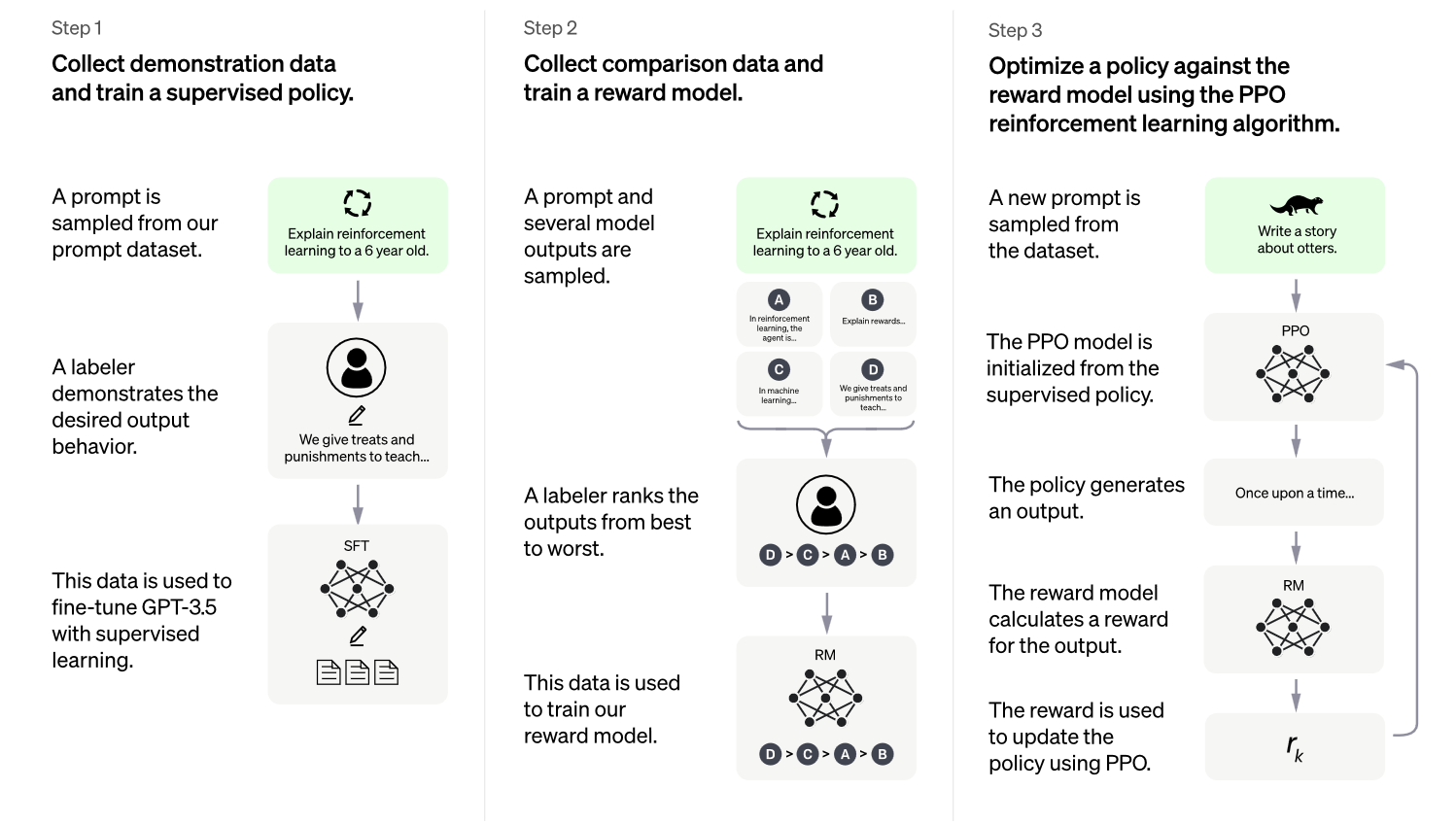
The three step LLM training process outlined in the ChatGPT paper.
One of the core challenges addressed in a recent paper titled “Direct Preference-based Policy Optimization without Reward Modeling” is the difficulty in obtaining an accurate reward model solely from preference information. Designing a quantitative reward function that accurately reflects desired behaviour can be a complex task, especially when human preferences are involved. Empirically, it has been observed that reward models learned from preferences often fail to accurately capture the underlying reward structure. This limitation poses a significant problem, as the quality of the learned policy in the current preference-based RL framework heavily relies on the quality of the learned rewards.
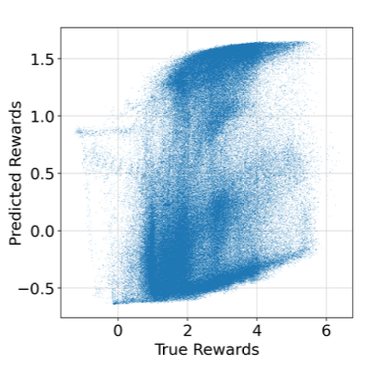
The reward model fails to accurately capture the underlying reward structure
To overcome this challenge, the paper introduces a novel preference-based RL approach that eliminates the need for reward modeling. The core idea is to leverage the contrastive learning framework to design a policy scoring metric that assigns high scores to policies that align with the given preferences.
The proposed method bypasses the need for training a reward function model by directly learning from preference labels. By formulating the objective as a contrastive learning problem, the algorithm guides the policy to be closer to more preferred trajectory segments while distancing itself from the less preferred ones. This approach improves the accuracy of the learned policy and overcomes the challenges associated with accurately capturing the reward structure from preference information.
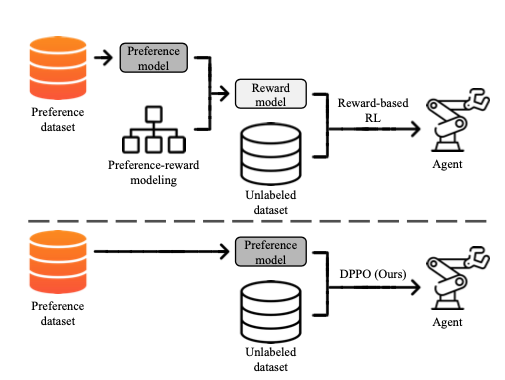
Difference between the traditional PPO method vs the DPO method proposed in the paper.
The experiments conducted in this study focused on the application of direct preference-based policy optimization (DPPO) to fine-tune large language models using human preference data. The researchers utilized human preference datasets to train preference models and evaluated the performance of the tuned language model through human evaluation. By replacing the traditional PPO algorithm with DPPO, they were able to eliminate unnecessary assumptions typically required for reward-based policy optimization. The following table demonstrates the improved win rate by using the DPO algorithm for LLMs fine-tuning.

RLHF results using DPPO (ours) compared to PPO. The values in the parentheses denote the gain on average reward compared to the original model.
To learn more about the details of this research and its impact, please refer to the original paper.
References
- Direct Preference-based Policy Optimization without Reward Modeling Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, Hyun Oh Song